Оригинал материала
Как устроено управление контентом в «Медузе»?
Рассказываем все технические подробности про нашу легендарную CMS-систему «Монитор»

«Монитор» — это сердце и мозг всех проектов и продуктов «Медузы». В первую очередь это система, в которой редакция создает все материалы, которые вы видите на нашем сайте и в мобильном приложении. Но не только: в «Мониторе» также формируется главная страница «Медузы» (точнее, главные — десктоп и телефоны по отдельности). А еще с помощью «Монитора» мы публикуем посты в соцсетях, загружаем видео на ютьюб, публикуем подкасты, рассылаем нашу ежедневную «Вечернюю Медузу» — и анализируем свою работу. В этом материале технический директор «Медузы» Борис Горячев рассказывает, как устроен продукт, созданный нами для нас самих.
История
«Монитор» написан на Ruby on Rails. Он использует PostgreSQL для хранения всех материалов «Медузы» и Redis как shared storage — «Монитор» в него пишет, а сервис, который формирует API для клиентов, читает, трансформирует API в нужную версию и отдает JSON.
Когда «Медуза» запускалась, «Монитор» работал так: каждый материал хранился в одной таблице posts, которая содержала колонки title (для заголовка), body (для текста), published_at (для времени публикации) и так далее. Обновлялся материал как один объект.
Такой «классический» подход — главное, что приходит в голову, когда нужно сделать любую систему управления контентом (CMS). Но первая проблема, с которой мы столкнулись, — одновременное изменение материала несколькими редакторами. Дело в том, что при «классическом» подходе при сохранении материала все его атрибуты уходят на сервер вместе. Поэтому если два человека пытаются редактировать один и тот же текст, один из них, скорее всего, уничтожит работу другого, пересохранив материал со своими правками.
Мы сразу не хотели идти путем, когда один редактор полностью бы блокировал материал и делал его недоступным для редактирования всеми остальными. Поэтому мы кое-как решили эту проблему, написав немного JavaScript и немного web-сокетов для того, чтобы делать частичные обновления материала. Код был страшненьким, но он работал.
Вторая проблема появилась, когда «Медуза» начала придумывать форматы. Мы начали делать это не сразу — но когда начали, оказалось, что изначальная архитектура слабо под это подходила.
Дело в том, что редакция стала мыслить не только текстовыми форматами — новость, интервью, рецензия и так далее, — но и техническими: например, слайды, тесты, игры. Любой из этих форматов обладает набором характеристик, которые, собственно, и делают из него что-то уникальное. К примеру, новость — самый простой технический формат, который определяется одним заголовком, одним полем под текст, местом под источник и местом под контекст. А фичер (который мы используем под длинные тексты, интервью и множество других видов материалов) вдобавок к тому, что есть у новости, обладает еще подзаголовком, заходной картинкой и лидом. К тому же у него два режима верстки: обычный и на всю ширину (без баннера справа и с шапкой текста по центру).
Карточки — титульный формат рубрики «Разбор» — вообще состоят из серии собственно карточек, каждая из которых состоит из своего заголовка и текста. А вместо заходной картинки материалы используют специально нарисованную под конкретный материал иконку.
Когда мы запустились, у нас был только один специальный формат — карточки. У карточек были как обычные атрибуты, встречающиеся у других материалов — заголовок, картинка, — так и объект, который представлял собой коллекцию собственно карточек (то есть блоков с вопросом и ответом). Мы стали хранить его просто в JSON, но он работал как один атрибут, несмотря на то, что в нем было какое-то количество заголовков (вопросов) и текстов (ответов).
Это работало какое-то время, но потом «Медуза» начала придумывать другие форматы, и с каждым месяцем становилось понятнее, что подход с единой таблицей нам перестал подходить. В каждом случае приходилось делать специальный js-код, который поддерживал JSON и отличал один материал от другого. Добавлялись проблемы с сохранением этого JSON — и невозможно было работать с ним по частям.
Как написано выше, кроме возрастающей сложности кода на Ruby, мы начали сталкиваться с тем, что в каждом случае для каждого типа материала приходилось писать свой фронтенд, который, понимая тип материала, менял код формы. В итоге все стало разношерстным. На это еще наложилась ограниченность в ресурсах: долгое время в техотделе не было человека, который бы прицельно занимался фронтендом «Монитора».
Первый подход к переписыванию ключевых компонентов на JavaScript произошел к перезапуску сайта «Медузы», когда на главной странице появилась сетка материалов: мы выбрали AngularJS и сделали на нем редактор главной страницы (работающий до сих пор). После этого мы переписали код формы и унифицировали его. Если говорить о происходящем «под капотом», модель данных поменялась не сильно, но хотя бы для редакторов «Медузы» все форматы стали выглядеть плюс-минус одинаковыми.
Еще надо сказать, что появление новых форматов — процесс, который невозможно предсказать. Иногда идей очень много, а иногда их нет, и технический отдел может месяцами заниматься другими задачами.
Но время шло, мы добавляли поведение в существующие форматы и становилось понятно, что существующая модель требовала полного переосмысления. Так мы пришли к новому подходу, который должен был решить следующие задачи:
- универсальность поведения компонентов, из которых состоит материал,
- возможность менять порядок вывода компонентов без похода в JS,
- возможность добавлять или скрывать компоненты,
- наличие максимально простых и чаще всего не связанных друг с другом кусочков данных, из которых можно было бы собирать контент под нужды клиентов,
- возможность перенести данные из старой модели в новую, сохранив весь контент.
Вместе с тем, конечно, была задача оставить обратную совместимость у всех клиентов: веба, приложений, RSS и всего остального, что собиралось из «старых» данных. В некоторых компаниях при редизайнах делают архив материалов. Оставляют данные старых материалов как есть, оставляют под них логику вывода и двигаются дальше. Мы решили, что перенесем все, что было к тому моменту на «Медузе», на новую архитектуру. То есть самые первые материалы «Медузы» должны работать и выглядеть так, будто они были сделаны сегодня.
Фабрика материалов
Очень абстрактно идея новой архитектуры формулировалась так: что если представить любой материал как коллекцию разных по сложности атрибутов, которые могут редактироваться изолированно друг от друга, по необходимости удаляться или добавляться или содержать в себе «ссылки» на другие материалы?
Абстракция детализировалась в такую модель: есть post, который не содержит никаких данных о том, из чего он «собирается». Есть components — компоненты, которые принадлежат посту — с псевдотипом, и детерминированная этим типом структура value — собственно, значения, с которыми работает редактор и из которых в конце концов получается что-то осмысленное на страницах «Медузы». Еще у компонента есть порядок вывода: заголовок идет первым, после него — тело материала, дальше — другие поля.
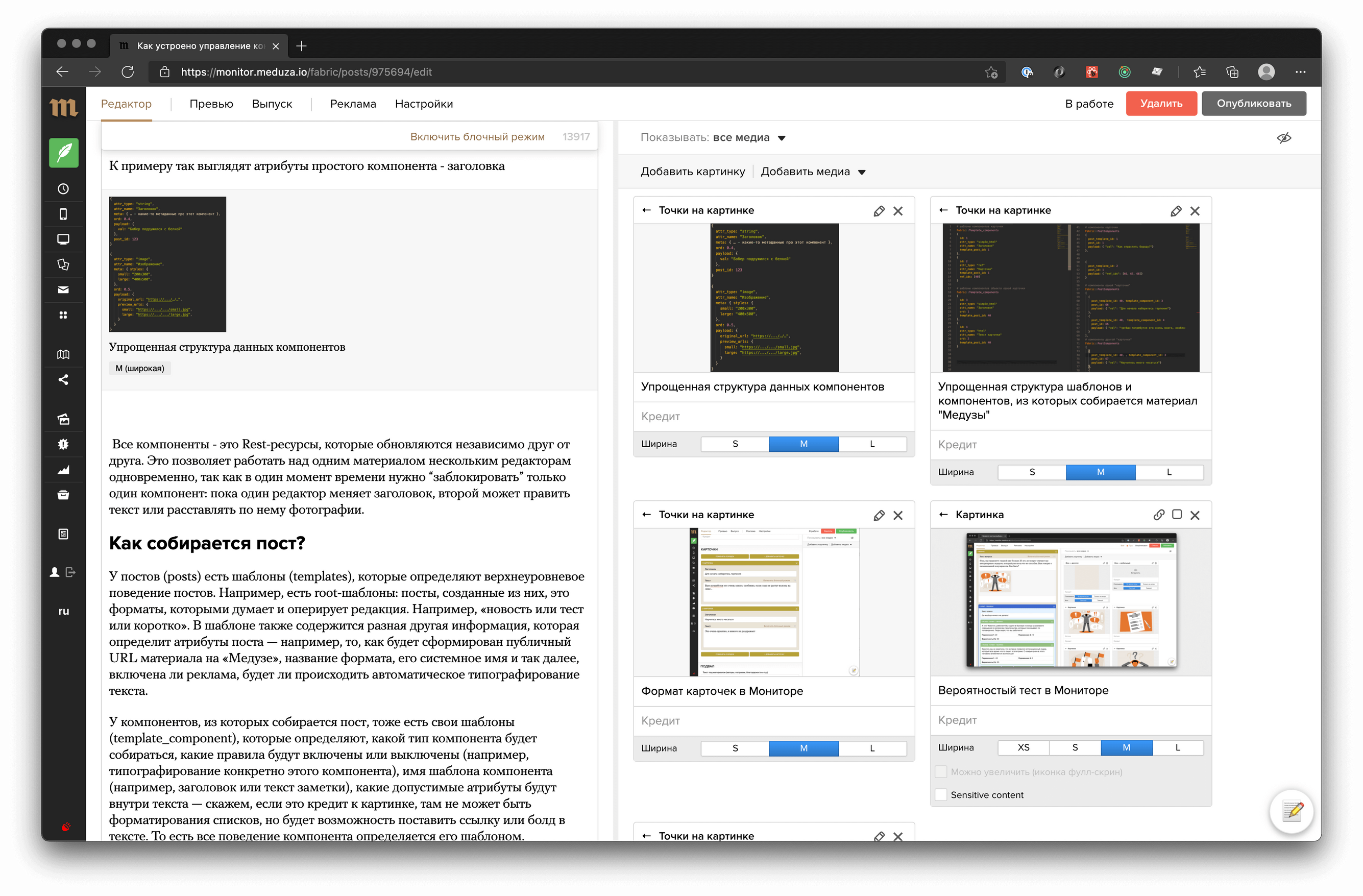
К примеру, так выглядят атрибуты простого компонента — заголовка.
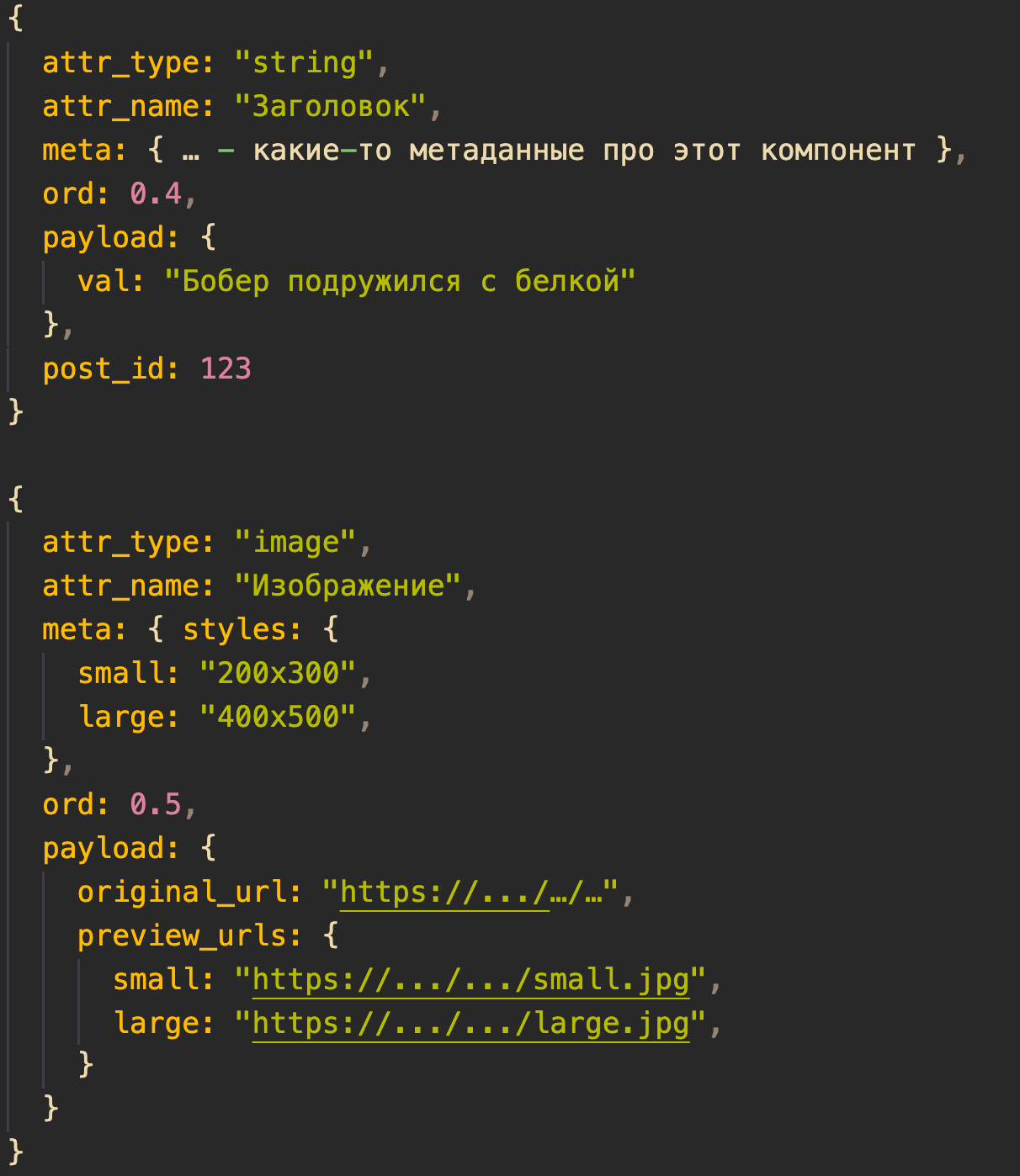
Это «псевдотип» комопнента, который нужен нам для того, чтобы понимать с чем мы имеем дело и на фронтэнд (react приложении, которое обслуживает монитор) и на бэкенде (rails приложение и другие сервисы, которые формируют JSON-ы для «Медузы»)
Порядок вывода.
Это значение используется только фронтэндом в «Мониторе», для того, чтобы выводить компоненты в правильном для редакции порядке. Заголовок пойдет первым, подпись к материалу — последней.
Связь с постом, которому принадлежит компонент.
Это стандартная связь объектов в Active:record (ORM ruby on rails)
Название поля для редактора.
Это просто лейбл, на который ориентируется редактор, когда работает с материалов в тексте
Payload компонента.
В зависимости от attr_type payload — те данные, которые определяют значение, которое хранить компонент могут быть представлены в том формате, который лучше всего подходит. Это всегда JSON, но он всегда разный, у разных типов
Все компоненты — это Rest-ресурсы, которые обновляются независимо друг от друга. Это позволяет работать над одним материалом нескольким редакторам одновременно, так как в один момент времени нужно «заблокировать» только один компонент: пока один редактор меняет заголовок, второй может править текст или расставлять по нему фотографии.
Как собирается пост?
У постов (posts) есть шаблоны (templates), которые определяют верхнеуровневое поведение постов. Например, есть root-шаблоны: посты, созданные из них, — это форматы, которыми думает и оперирует редакция. Например: новость, тест или коротко. В шаблоне также содержится разная другая информация, которая определит атрибуты поста — например, то, как будет сформирован публичный URL материала на «Медузе», название формата, его системное имя и так далее, включена ли реклама, будет ли происходить автоматическое типографирование текста.
У компонентов, из которых собирается пост, тоже есть свои шаблоны (template_component), которые определяют, какой тип компонента будет собираться, какие правила будут включены или выключены (например, типографирование конкретно этого компонента), имя шаблона компонента (например, заголовок или текст заметки), какие допустимые атрибуты будут внутри текста — скажем, если это кредит к картинке, там не может быть форматирования списков, зато будет возможность поставить ссылку или болд. То есть все поведение компонента определяется его шаблоном.
Кроме простых компонентов — текст, галочка или картинка, — у нас есть еще компоненты, которые умеют держать связь с другими постами. Их шаблон определяет, какие посты могут прикрепиться к этому компоненту. Запутались? Объясним на примере формата карточки.
Устройство шаблонов и шаблонов компонентов
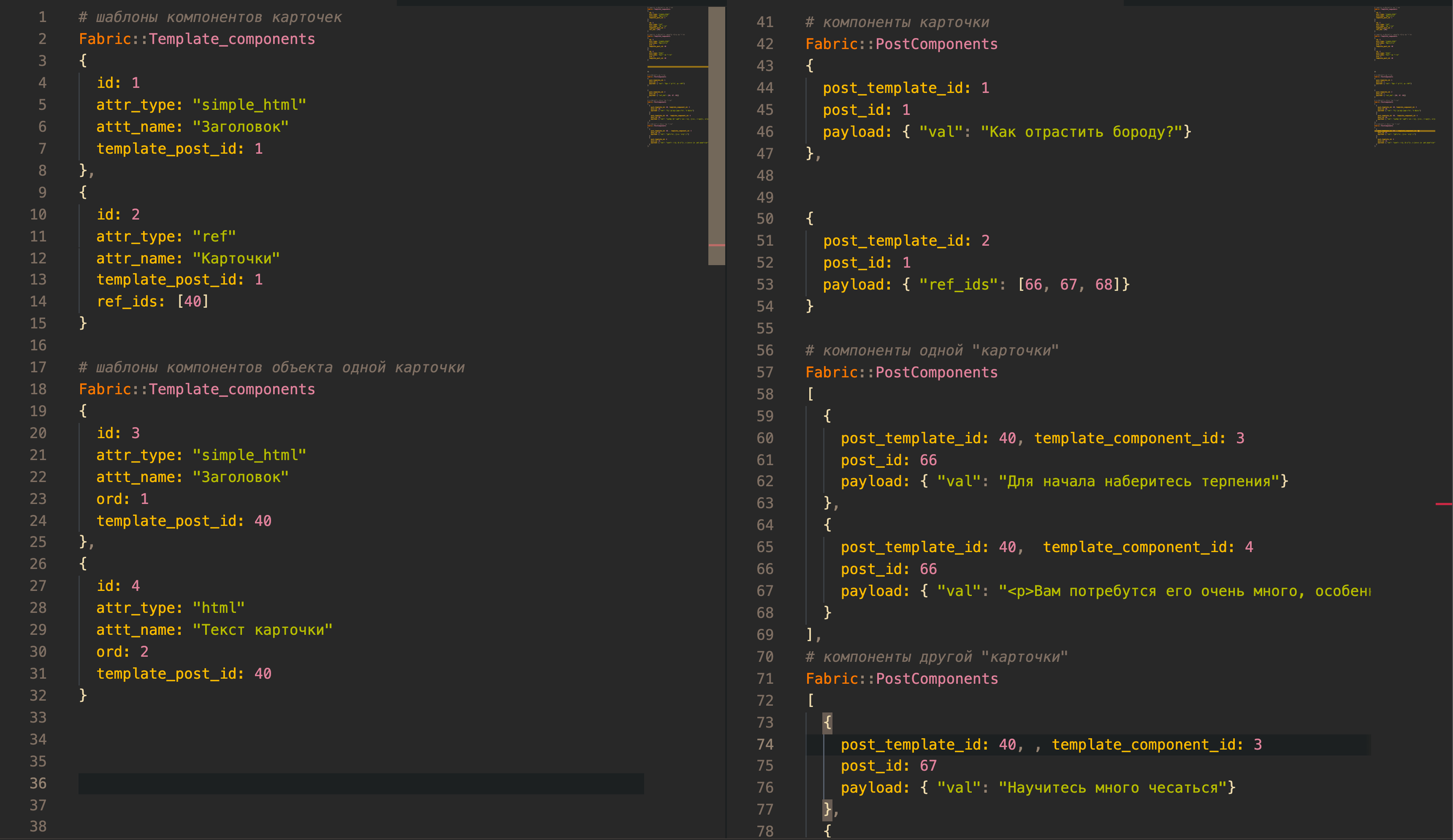
Это короткая версия шаблонов, которые определяют то, как будут вести себя компоненты
Связь с «шаблонами-детьми».
Шаблон с attr_type: ref предполагает, что к нему будут «прицепляться» другие посты. В данном случае все посты, которые будут прицепляться, будут собраны из шаблона с id: 40
Коллекция пост-компонентов, которые находятся «внутри».
Эти пост компоненты находятся внутри материала «Карточка»
Каждый компонент связан со своим шаблоном.
Именно из-за этой связи компонент понимает, как ему надо себя вести
А так это выглядит в «Мониторе»:
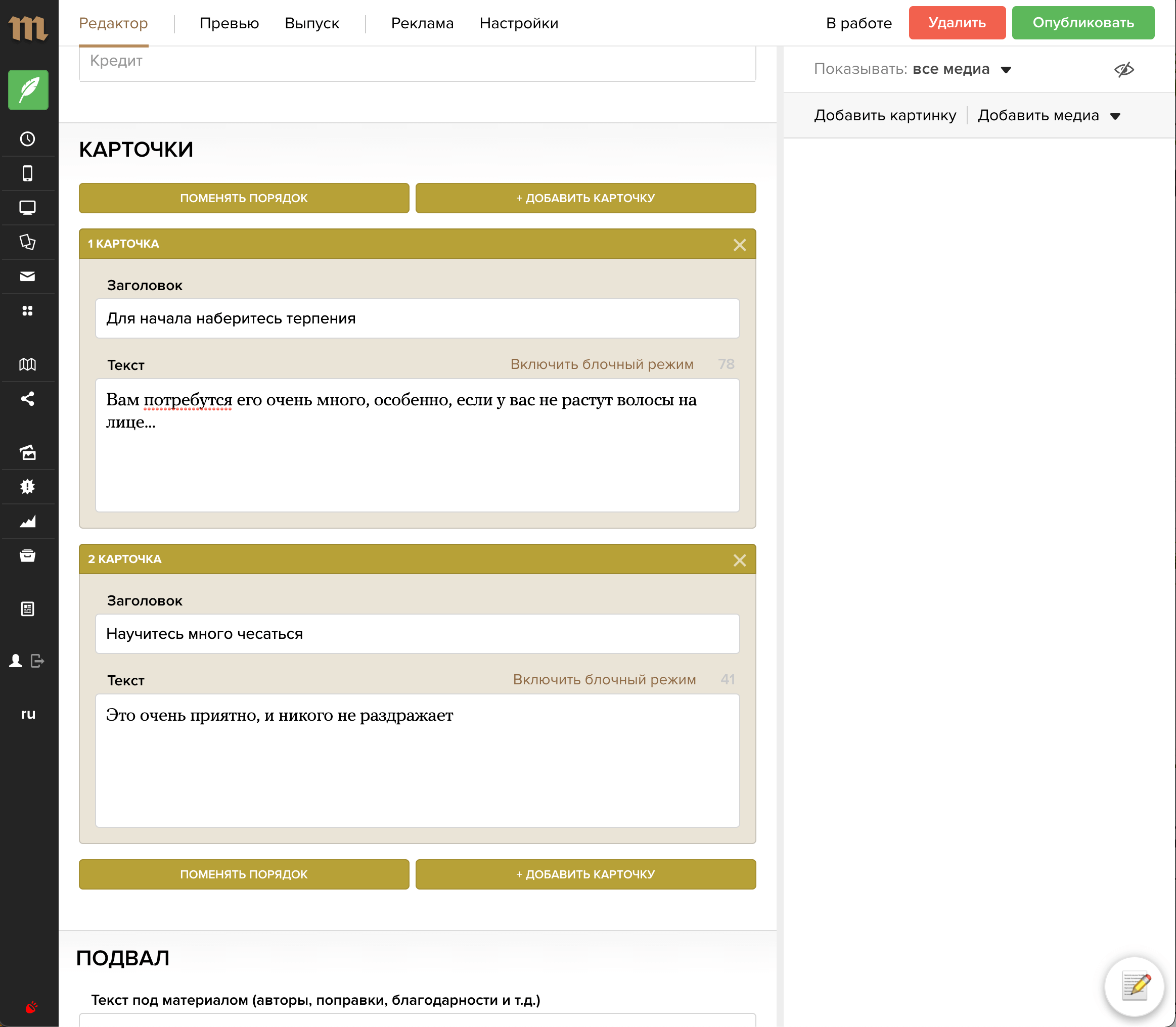
Это пост-компонент, который держит связь (через ref_ids) с коллекцией постов ниже
Пост «карточки».
Он состоит из заголовка и текста
Пост-компонент с типом simple_html.
Это заголовок одной карточки
Пост-компонент с типом html.
Это текст, в котором доступны все выразительные средства «Медузы» — заголовки, списки и так далее.
Управление постами.
Эти кнопки позволяют создавать новые вложенные посты в коллекции «Карточки». Под капотом происходит запрос в монитор, который создает новый пост из двух компонентов и «связывает» его через ref_ids в пост-компонентом карточек
Вложенность постов в нашем случае никак специально не ограничена, но самый «глубокий» уровень, которого мы достигали, — 3. Такая глубина нужна нам в самой сложной игровой механике — вероятностном тесте.
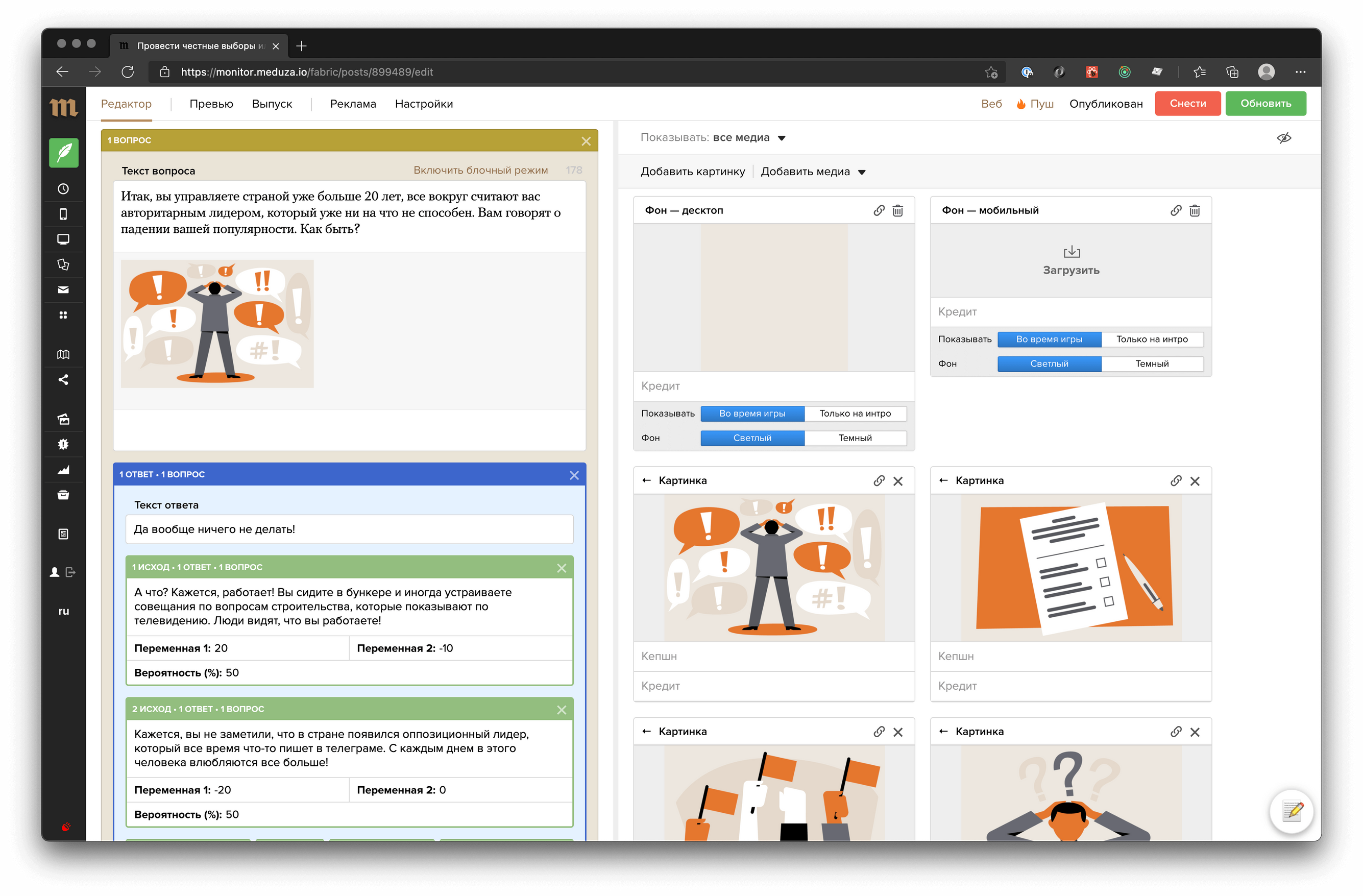
В нем есть:
- вопросы (первый уровень),
- варианты ответов (второй уровень),
- варианты исходов (третий уровень — случайный исход, который наступит, если читатель выбирает этот ответ).
Как устроена форма редактирования материала
Когда редактор открывает форму редактирования материала, происходит несколько вещей:
- Загружается страница монитора с плейсхолдером под react,
- Загружается React-приложение,
- Оно забирает JSON, которое ему отдает Rails-бэкенд,
- Оно же подключается к websocket-серверу, который написан на Elixir и Phoenix Framework.
Структура, которую получает React, упрощенно выглядит так:
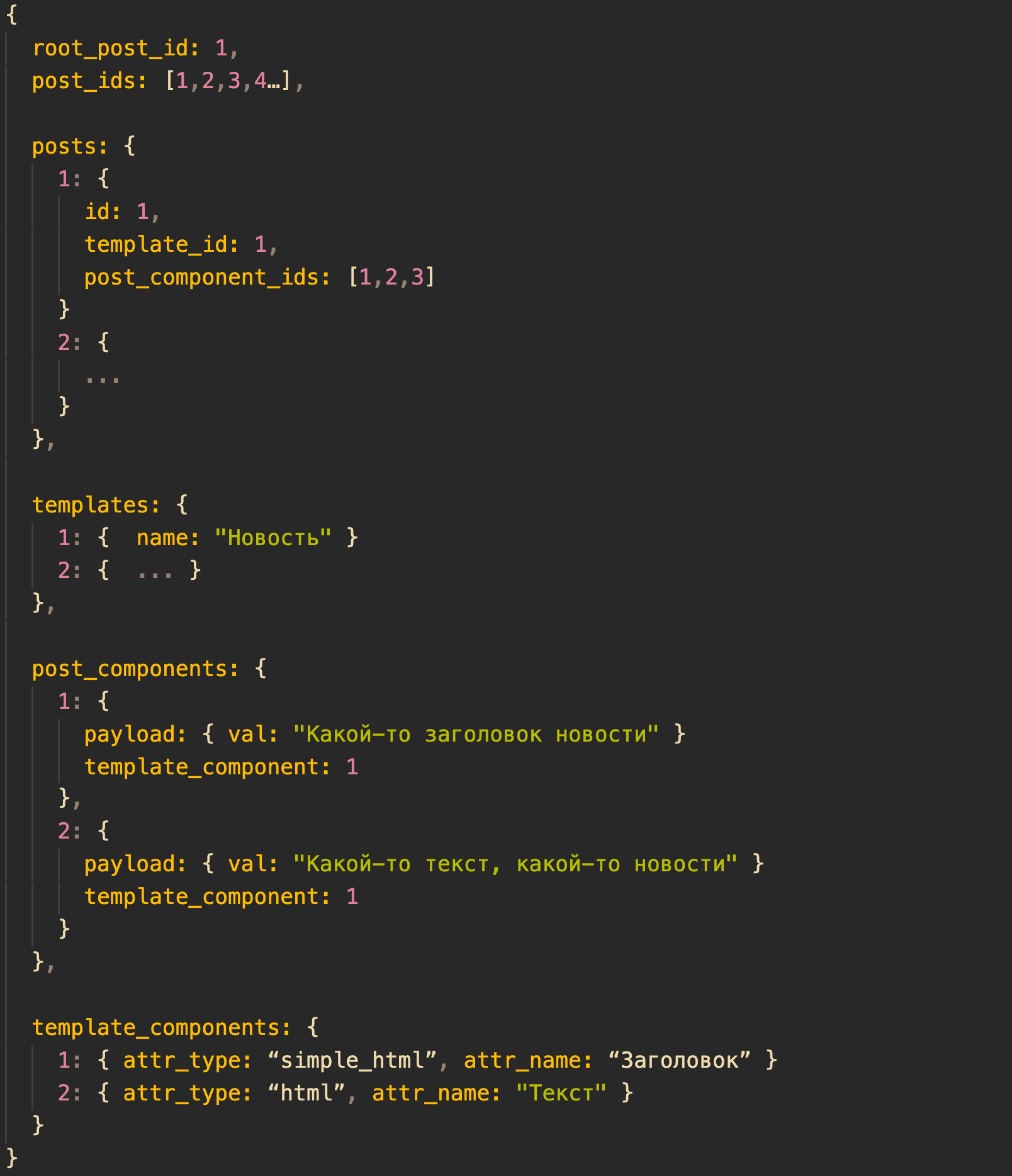
Это и главный пост, и вспомогательные, например, эмбеды, картинки, сноски и тд.
Пост компоненты, из которых состоит пост.
Из этих пост-компонентов собирается пост, тут это список id, которые будут забираться из post_components[id]
Шаблоны постов.
Эти шаблоны нужны в первую очередь для нейминга
Компоненты.
Все компоненты, которые использованы в форме лежат в этом атрибуте. Не важно — это компоненты root поста или тех постов, которые находятся где-то глубоко внутри формы
Шаблоны компонентов.
Содержат данные, которые нужны для того, чтобы определить тип компонента, добавить ему label, ограничить количество символ и так далее
React-приложение берет root_post_id, переходит в posts, находит компоненты этого поста по id и начинает «рендерить» их. При этом оно забирает «типы» — и в каждом случае рендерит компонент под тот тип, который забирает из template_components. В случае когда компонент является референсом на коллекцию других постов, все это происходит рекурсивно, с передачей внутрь разных параметров относительно того, как глубоко мы прошли в рендер.
Каждый компонент имеет свои эндпоинты — типа fabric/post_components:id, edit, delete — и обновляется независимо от других.
Помимо этого, есть специальные эндпоинты под создание постов, которые находятся «внутри» других постов, — им для создания нужен тип шаблона, в котором они должны создаваться, и какие-то необязательные параметры, которые могут определить, к примеру, как много постов одного типа надо создать за раз. Они также могут создавать не только себя, но и все дерево под собой.
Когда происходят события создания или редактирования («удаления» у нас нет, только маркирование сущностей как архивных), Rails-бэкенд делает свои операции и отвечает React-приложению JSON-ом, который вмердживается в дерево redux стейта.
React, помимо того, что мерджит состояние (state), также отправляет кусок этого состояния в сокеты, и этот state рассылается всем клиентам, которые «слушают» — открытые браузеры других редакторов, которые находятся в материале. На стороне других браузеров происходит примерно то же самое, что и на оригинаторе изменений, за исключением того, что в их случае обновляемый компонент заблокирован.
Elixir занимается не только рассылкой, но и держит state, который через него проходил, в памяти — это нужно, чтобы новый редактор, когда он подключается к материалу, получил не только данные от Rails, но и еще информацию о потенциально заблокированных компонентах и о редакторах, которые сейчас находятся в том же материале. Состояние хранится в ETS-таблице и на каждый ивент обновляется, удаляя или добавляя данные.
То есть когда редактор входит на страницу материала в «Мониторе», сначала происходит построение формы по state, который пришел от Rails, а потом на него накладывается состояние, приходящее от Elixir.
Еще в паре мест, где Rails делает слишком много работы (и ее надо доставить всем и сразу), он иногда стучится напрямую в Elixir по HTTP, передавая туда сразу много разных данных. Например такое происходит, когда редактор вставляет в текст эмбед. Если нужно вставить YouTube-видео — редактор вставляет ссылку на видео, «Монитор» определяет, что идет работа с эмбедом, делает запрос в oembed youtube, забирает оттуда, находит внутри поста, куда вставлена ссылка caption и credit, обновляет эти поля данными, которые он получил из oembed, и отправляет их в Elixir-приложение. Оно делает broadcast всем, кто слушает, и все видят новые тексты.
Как устроено редактирование текста и вставка медиа
Мы используем WYSIWYG-редактор Quill. Мы выбрали его потому, что в то время, когда мы искали подходящее решение, он единственный умел хорошо работать с операциями выделения, копирования и вставки. А это было одним из требований от редакции: надо, чтобы можно было выделить и вырезать все что угодно — и потом вставить это куда захочется.
Это, казалось бы, не очень жесткое требование оказалось выполнить довольно сложно, когда стало понятно, что нельзя просто так вставить в WYSIWYG какой-то блок (например, картинку с подписью и кредитом), который бы работал атомарно при выделении, но при этом позволял бы редактировать текст, относящийся к медиа (те самые подпись и кредит). Да и вставка в текст эмбедов работала так себе.
В итоге мы реализовали, наверное, самое странное решение, которое при этом работает максимально предсказуемо и позволяет редакции видеть медиа в тексте, но не добавляет головной боли техотделу: мы рендерим превью эмбеда или картинки через SVG на стороне сервера. Выглядит это так:
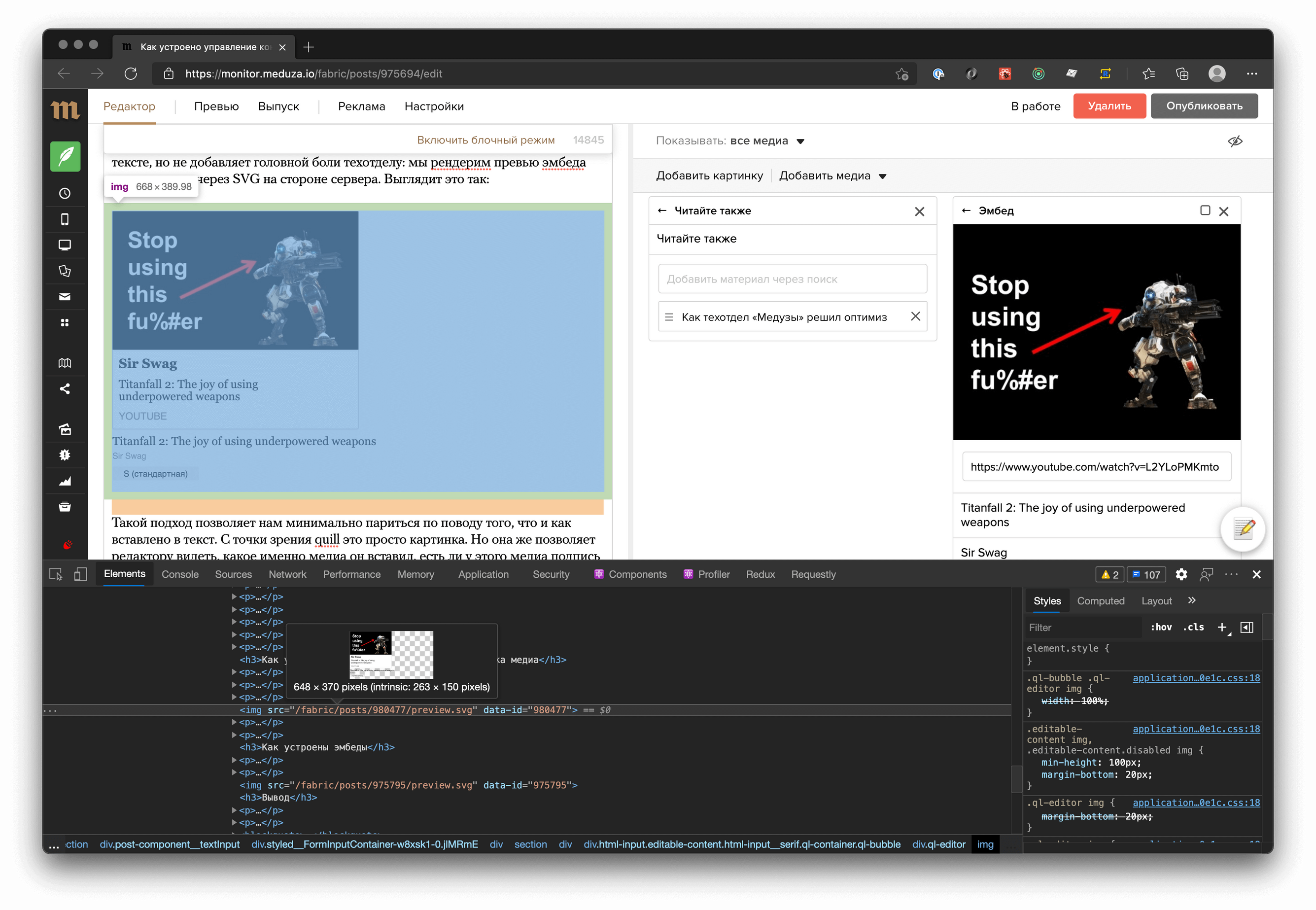
Она отдается через rails приложение, в контексте rails доступны: превью картинка из youtube (конкретно в этом случае), текст кепшена, кредита к ембеду, настройки ширины вывода
Как это выглядит в html внутри редактора.
Просто img с src, который отдает rails приложение. Тяжелые операции генерации этого svg кешируются. При этом, при изменении эмбеда (справа) происходит перегрузка картинки слева.
Сам «Эмбед».
В данному случае это youtube ролик, который вставлен по ссылке. Монитор сходил в oembed сервис youtube и забрал оттуда данные, которые заполнили thumnail, кредит и кепшен к материалу
Такой подход позволяет нам минимально париться по поводу того, что и как вставлено в текст. С точки зрения quill это просто картинка. Но она же позволяет редактору видеть, какое именно медиа он вставил, есть ли у этого медиа подпись и какой размер ему выставлен.
Этот подход также позволяет нам очень просто разбирать текст на блоки, из которых мы собираем API для клиентов. Но про это я напишу как-нибудь в следующий раз.
Как устроены эмбеды
Мы разделяем эмбеды — то есть вставленные в текст видео с ютьюба, твиты, посты в фейсбуке и так далее — на два типа: те, у которых есть oembed-версия — и у которых ее нет. Если у эмбеда есть oembed, «Монитор» по ссылке на видео или пост забирает JSON и использует его для показа картинки-превью, забора кепшенов, кредитов и HTML-кода. А если нет, редактор просто вставляет в поле HTML, который берет из сервиса.
Вместе со вставкой иногда происходят дополнительные операции — может немного поменяться HTML, что-то нормализоваться. Но мы стараемся особенно не менять то, что предоставляет провайдер, — эти трансформации происходят в другом месте, в сервисе, который готовит API для клиентов.
Она собирается на стороне rails, используя данные поста
А это пост.
Он собран из шаблона «Точки на картинках», и так как я обожаю рекурсию, этот пост находится внутри материала который я сейчас пишу, а этот текст, который вы сейчас читаете, находится в соседнем посте, который я пишу в поле, которое содержится в посте, который содержится в посте, который… в общем я запутался. Но! Это работает :)
Вывод
Наше решение может показаться довольно сложным, но за те несколько лет, что оно у нас работает, нам почти не приходилось писать js — когда надо добавить что-то новое, мы определяем структуры данных для редакции через данные, а не через код. Код формы на js един для всех материалов, от самых простых до самых сложных и навороченных.
В случаях, когда нам нужно суперспециальное поведение, мы вводим новые attr_type и вешаем на них дополнительную логику, которая может пойти в state и собрать что-то специальное. Но это не рушит поведение простых компонентов. А еще тот JSON, с которым взаимодействует React-приложение в «Мониторе», в почти таком же виде забирается Ruby-приложением, которое формирует все клиентские API «Медузы» — сайта, мобильного приложения и разных других сервисов. Но про это мы расскажем как нибудь в следующий раз.
Больше материалов о том, как мы делаем «Медузу», — в нашем блоге.
Борис Горячев, технический директор «Медузы»